 Toronto AI Lab
Toronto AI Lab
|
|
|
LATTE3D generates high-quality textured meshes from text robustly in just 400ms by combining 3D priors, amortized optimization, and a second stage of surface rendering. |
|
Abstract: Recent text-to-3D generation approaches produce impressive 3D results but require time-consuming optimization that can take up to an hour per prompt. Amortized methods like ATT3D optimize multiple prompts simultaneously to improve efficiency, enabling fast text-to-3D synthesis. However, they cannot capture high-frequency geometry and texture details and struggle to scale to large prompt sets, so they generalizes poorly. We introduce LATTE3D, addressing these limitations to achieve fast, high-quality generation on a significantly larger prompt set. Key to our method is 1) building a scalable architecture and 2) leveraging 3D data during optimization through 3D-aware diffusion priors, shape regularization, and model initialization to achieve robustness to diverse and complex training prompts. LATTE3D amortizes both neural field and textured surface generation to produce highly detailed textured meshes in a single forward pass. LATTE3D generates 3D objects in 400ms, and can be further enhanced with fast test-time optimization. |

|
Kevin Xie, Jonathan Lorraine, Tianshi Cao, Jun Gao,
James Lucas, Antonio Torralba, Sanja Fidler, Xiaohui Zeng LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis |
|
Generating 3D objects has seen recent success on multiple fronts: quality (e.g., via surface rendering as in Magic3D), prompt-robustness (e.g., via 3D priors as in MVDream), and real-time generation (e.g., via amortized optimization as in ATT3D). We combine these benefits into a text-to-3D pipeline, allowing real-time generation of high-quality assets for a wide range of text prompts. |
|
Use case: We generate high-quality 3D assets in only 400ms for a wide range of text prompts, with an option to regularize towards a user-specified 3D shape. |
|
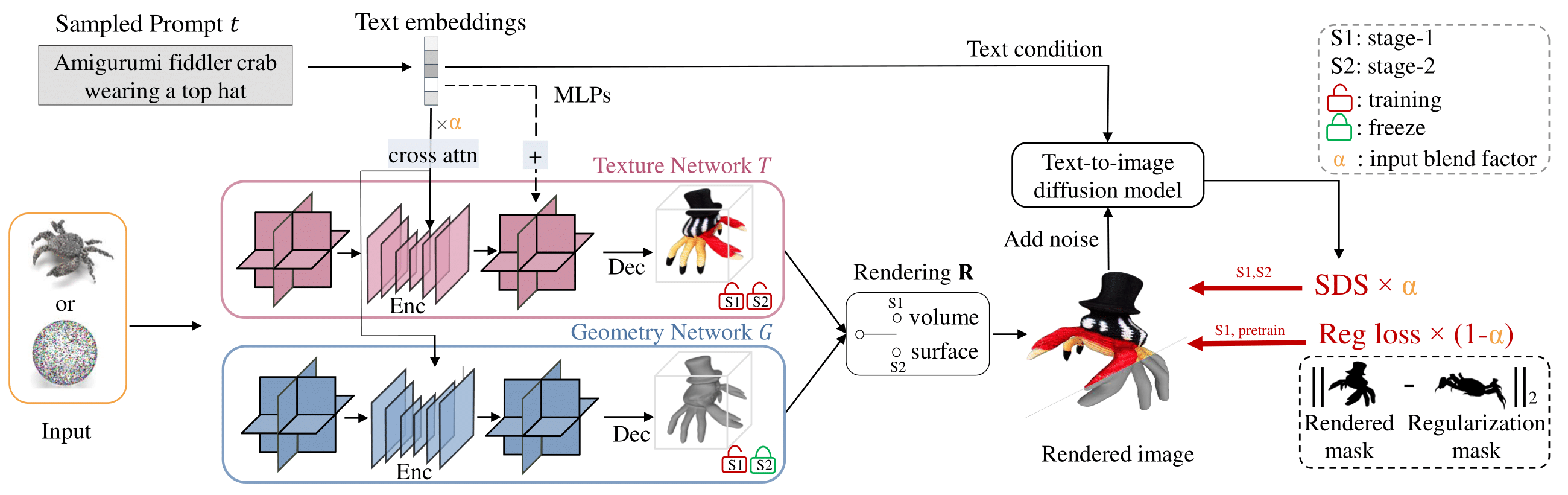
LATTE3D consists of two stages: First, we use volumetric rendering to train the texture and the geometry. To enhance robustness to the prompts, the training objective includes an SDS gradient from a 3D-aware image prior and a regularization loss comparing the masks of a predicted shape with 3D assets in a library. Second, we use surface-based rendering and train only the texture to enhance quality. Both stages used amortized optimization over a set of prompts to maintain fast generation. |
|
|
Our method uses two networks: a texture network T and geometry network G, both consisting of a combination of triplanes and U-Nets. In the first stage, the encoders of both networks share the same set of weights. In the second stage, we freeze the geometry network G and update the texture network T, and further upsample the triplanes with an MLP inputting the text embedding. |
|
Our trained models allow users to provide various text prompts and interactively view high-quality 3D assets. We improve the user experience by enhancing the 3D assets (a) quality, (b) generation speed, and (c) diversity of supported prompts. |
|
To test generalization to arbitrary prompts, we train our model on a larger set of 100k prompts, constructed by using ChatGPT to augment the captions of the lvis Objaverse subset. We generalize to unseen, in-distribution augmented captions. Even more, we generalize to unseen, out-of-distribution prompts from DreamFusion. |
|
We investigate our method for user stylization, enabled by our optional point cloud input. We train on a large set of prompts for realistic animals, where each user-supplied point cloud is stylized for varying text prompts. |
|
We expand the realistic animal stylization by training our method on animals composed with different styles. Our training prompts follow the template "object A in style B is doing C." We hold out combinations of objects, styles, and activities, showing similar generalization as ATT3D, with higher quality from our surface rendering in stage 2. |
|
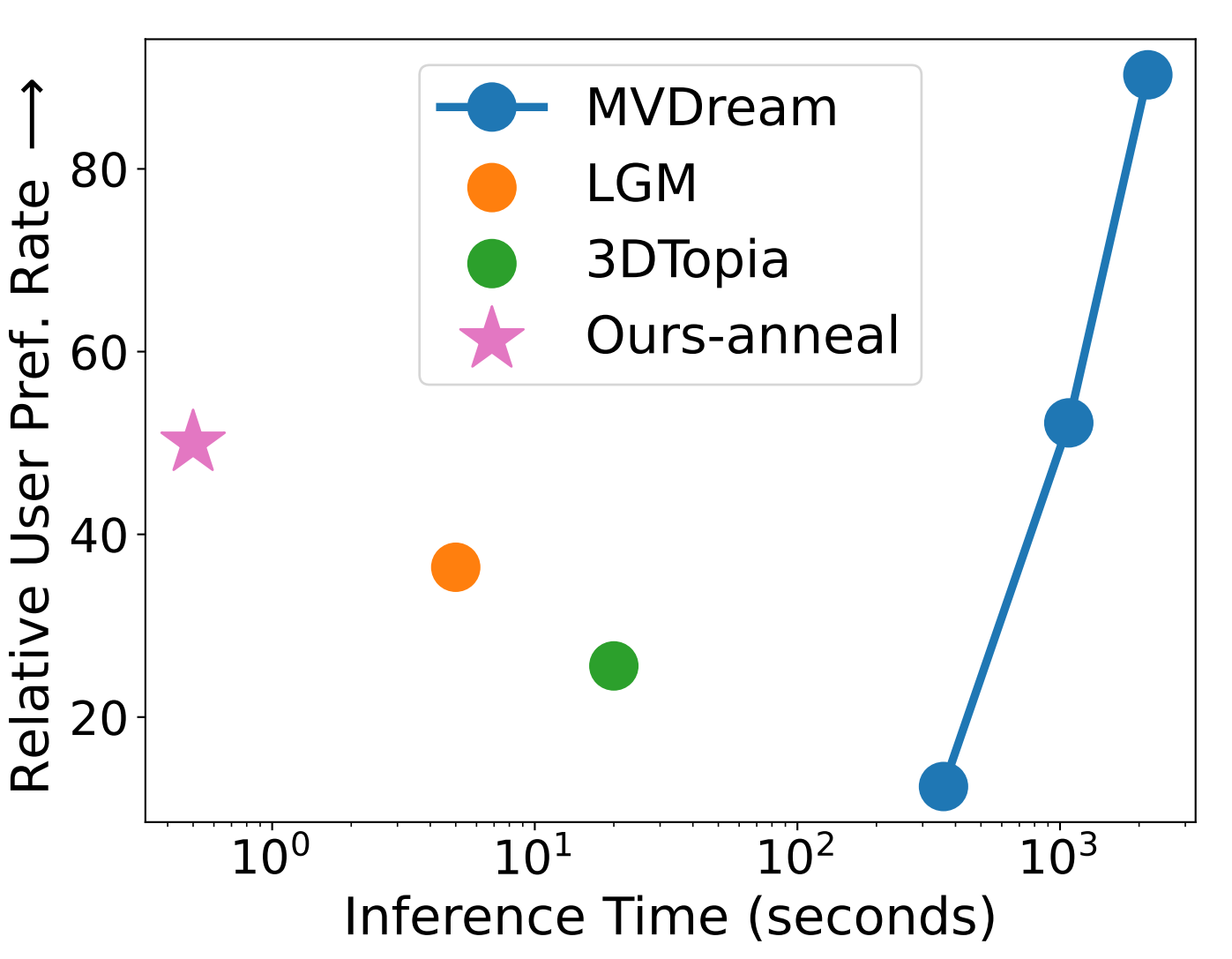
We compare against MVDream, 3DTopia, LGM, and ATT3D, where we show MVDream after 6 minutes, 30 minutes, and 1 hour of optimization. For ATT3D and LATTE3D, we show the inference on unseen prompts, which require 400ms. We plot the inference time and user study preference rates of different methods compared to LATTE3D, where a rate below 50 indicates a preference for LATTE3D on average. We desire methods that are in the upper-left of the figure. |
|
|
We provide a list of the DreamFusion prompts here: df67 prompts. Below, we include examples of the results used in the user study. |
|
Users can quickly design entire scenes with one of our models by rapidly iterating on an individual object's design or the collection of objects they use. We generate each prompt's result at interactive rates, with up to 4 samples per prompt on an A6000 GPU. |
|
We support an optional, fast test-time optimization when a user desires a further quality boost on any prompt. |
|
We allow users to guide generalization towards a user-provided shape (as a point-cloud), which is a 3D analog of image-conditioning for text-image generation. To do this, we also amortize optimization over a point cloud regularization weight, which a user can control cheaply at inference time. When the weight is high, we recover the point cloud's shape, while when the weight is low, the text prompt primarily guides the model's generation. |
|
We use LATTE3D to initialize text-to-4D methods, such as Align Your Gaussians. |
|
Citation
|
|
Xie, K., Lorraine, J., Cao, T., Gao, J., Lucas, J., Torralba, A., Fidler, S., & Zeng, X. (2024). LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis. The 18th European Conference on Computer Vision (ECCV).
@article{xie2024latte3d,
|